|
I've just uploaded a preprint to bioRxiv (http://www.biorxiv.org/content/early/2017/08/16/177253) that describes the Oyster River Protocol. In short, the protocol user a multi-assembler and multi-kmer approach to generating transcriptome assemblies. Because each individual assembler carries with it biases, leveraging multiple assemblers each of which complement the other results in a really great assembly. The users guide is here: http://oyster-river-protocol.readthedocs.io/en/latest/ To benchmark the protocol, I used 15 publicly available RNAseq datasets of different sizes. All were eukaryotes. Here are the highlights.
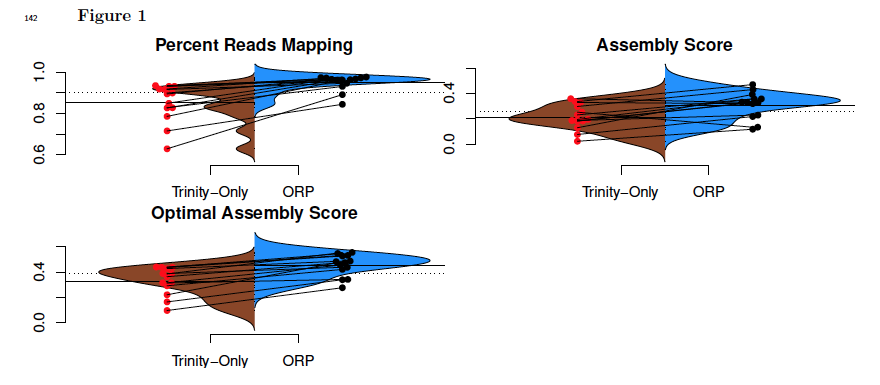
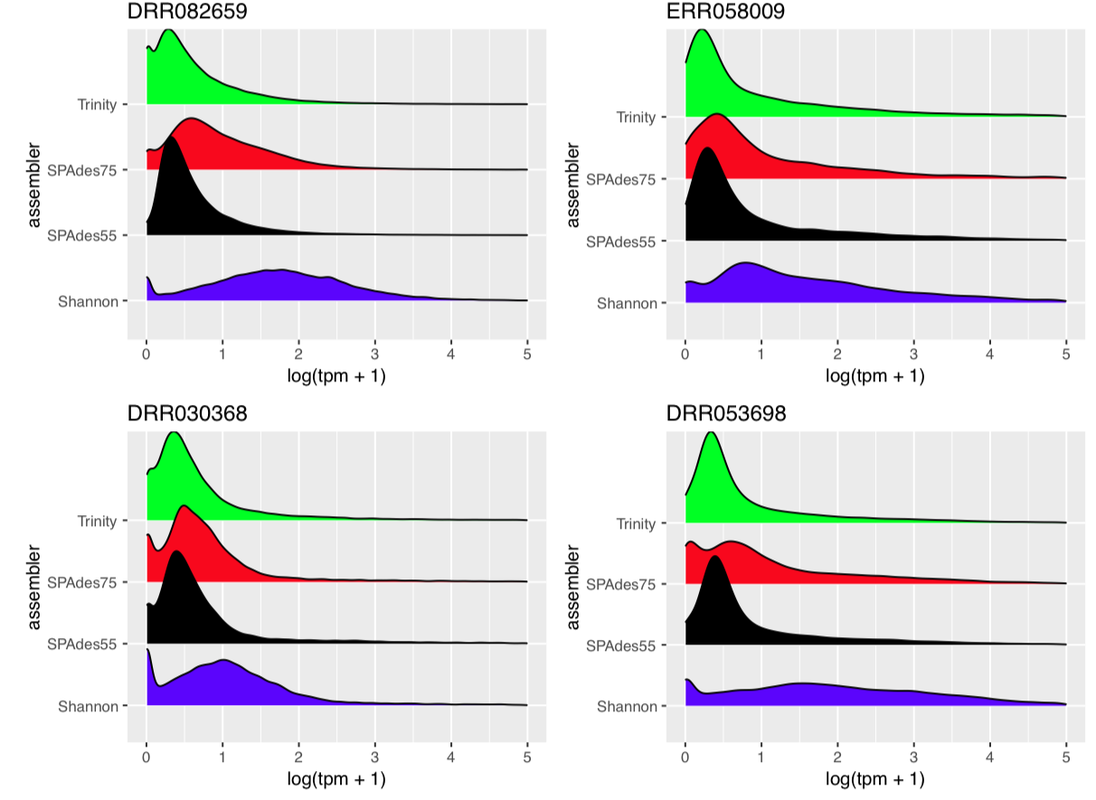
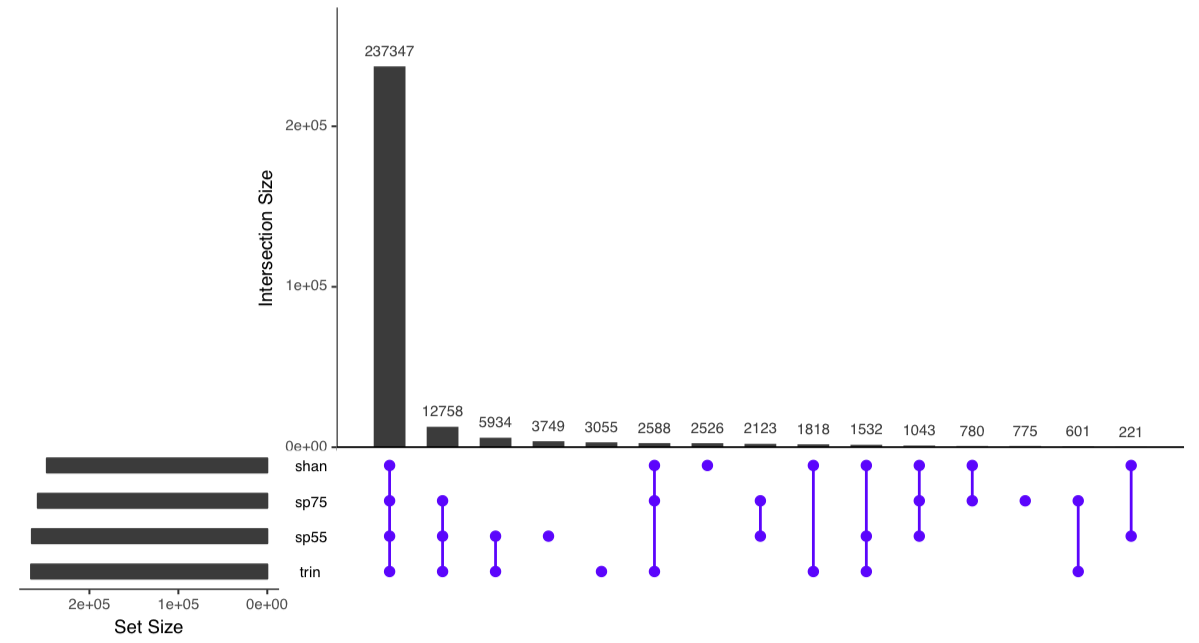
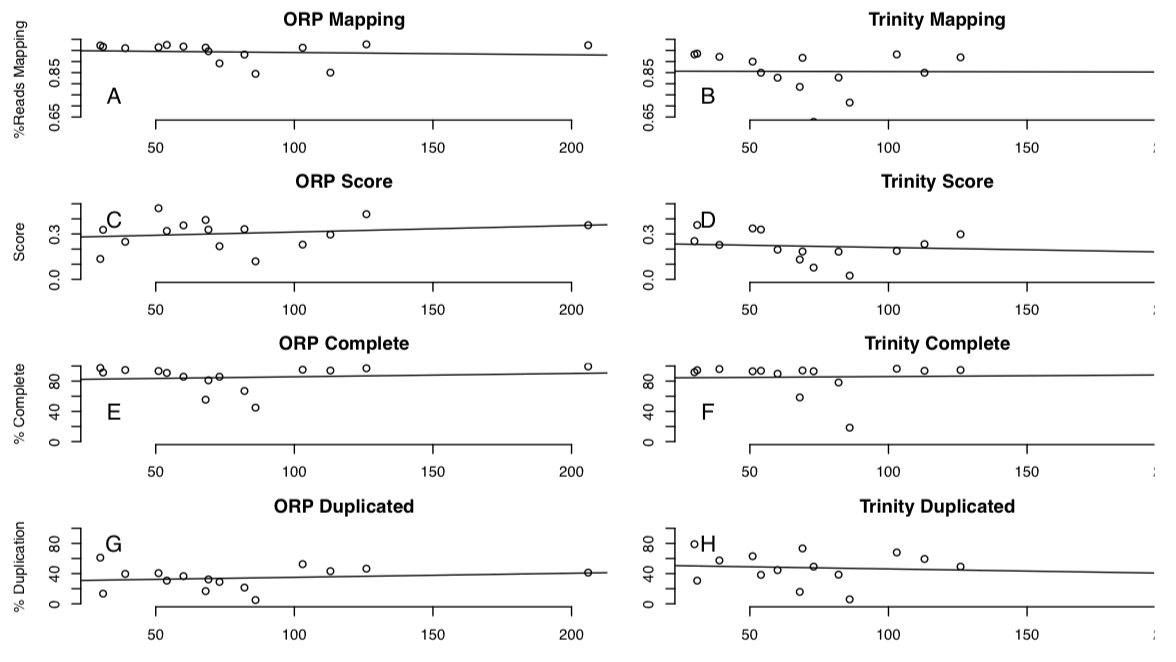
19 Comments
|
AuthorWrite something about yourself. No need to be fancy, just an overview. Archives
August 2017
Categories |
 RSS Feed
RSS Feed
